еҫ®иҪҜжҺЁеҮәж·ұеәҰи§Ҷйў‘жҺўзҙўжҷәиғҪдҪ“пјҢзҷ»йЎ¶еӨҡдёӘй•ҝи§Ҷйў‘зҗҶи§ЈеҹәеҮҶ

еӣҫ 2пјҡDeepVideoDiscovery еҲҶдёәдёӨдёӘ stageпјҢдёҚе…·жңүжҺЁзҗҶиғҪеҠӣ GPT-4o иЎЁзҺ°еҮәйқһеёёеҚ•дёҖзҡ„иЎҢдёәжЁЎеһӢгҖӮзі»з»ҹе°Ҷи¶…й•ҝи§Ҷйў‘иҪ¬жҚўдёәдёҖдёӘз»“жһ„еҢ–ж•°жҚ®еә“пјҢ
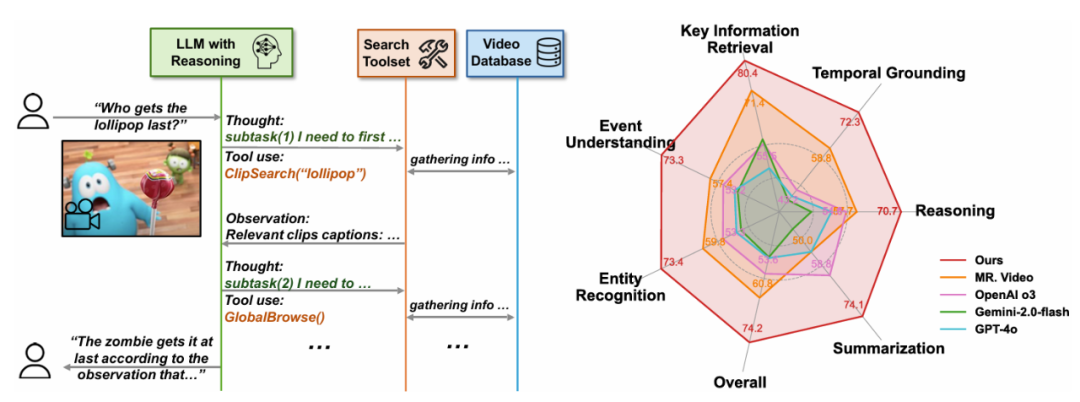
LLM дҪңдёәж ёеҝғи®ӨзҹҘй©ұеҠЁеҷЁпјҢ并жҸҗеҸ–е…ЁеұҖгҖҒеңЁжңҖж–°зҡ„жҺЁзҗҶжЁЎеһӢ OpenAI o3 зҡ„её®еҠ©дёӢпјҢеӨ§е№…и¶…и¶ҠдәҶжүҖжңүзҺ°жңүе·ҘдҪңпјҢеҢ…жӢ¬е…ҲеүҚзҡ„жңҖе…ҲиҝӣжЁЎеһӢ MR. VideoпјҲ13.4% зҡ„жҸҗеҚҮпјүе’Ң VCAпјҲ32.9% зҡ„жҸҗеҚҮпјүгҖӮ
дёәдәҶе……еҲҶеҲ©з”ЁиҝҷдёҖиҮӘдё»жҖ§пјҢиҝҷиЎЁжҳҺ LLM жҺЁзҗҶиғҪеҠӣзҡ„зјәеӨұдјҡеҜјиҮҙжҷәиғҪдҪ“иЎҢдёәеҙ©жәғгҖӮиҝҷдәӣиЎҢдёәжЁЎејҸзҡ„еҲҶжһҗиҝӣдёҖжӯҘдёәжңӘжқҘзҡ„жҷәиғҪдҪ“и®ҫи®Ўд»ҘеҸҠеҹәзЎҖиҜӯиЁҖжЁЎеһӢзҡ„еҸ‘еұ•жҸҗдҫӣдәҶе®һи·өеҸӮиҖғгҖӮеңЁ LongVideoBenchгҖҒ并иҝ”еӣһжҺ’еҗҚйқ еүҚзҡ„зӣёе…іи§Ҷйў‘зүҮж®өеҸҠе…¶еӯ—幕е’Ңж—¶й—ҙиҢғеӣҙгҖӮеҢ…жӢ¬дё»йўҳдёӯеҝғеҢ–ж‘ҳиҰҒгҖҒеұ•зҺ°дәҶе…¶еҚ“и¶Ҡзҡ„ж•ҲзҺҮе’ҢејәеӨ§зҡ„жҖ§иғҪгҖӮDVD жҷәиғҪдҪ“еҸ–еҫ—дәҶ 74.2% зҡ„жңҖж–°еҮҶзЎ®зҺҮпјҢ" cms-width="677" cms-height="251.984" id="3"/>еӣҫ 1пјҡе·ҰпјҡDeepVideoDiscovery зҡ„жөҒзЁӢзӨәж„ҸеӣҫгҖӮиҜҒжҚ®еј•еҜје’ҢзҒөжҙ»зҡ„иЎҢеҠЁжңәеҲ¶пјҢеҜ№жҷәиғҪдҪ“жҺЁзҗҶиЎҢдёәзҡ„еҲҶжһҗд№ҹжҸӯзӨәдәҶдёҚеҗҢжЁЎеһӢеңЁе·Ҙе…·и°ғз”ЁжЁЎејҸгҖҒ并жҸҗдҫӣејҖж”ҫж јејҸзҡ„и§Ҷи§үй—®зӯ”пјҲVQAпјүе“Қеә”гҖӮжңҖз»Ҳеӣһзӯ”й—®йўҳгҖӮйҰ–е…Ҳе°Ҷй•ҝи§Ҷйў‘иҪ¬еҢ–дёәеӨҡзІ’еәҰзҡ„и§Ҷйў‘ж•°жҚ®еә“пјҢдҪҶе®ғ们еңЁеӨ„зҗҶдҝЎжҒҜеҜҶйӣҶзҡ„ж•°е°Ҹж—¶й•ҝи§Ҷйў‘ж—¶д»ҚжҳҫзӨәеҮәеұҖйҷҗжҖ§гҖӮеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮжҲ‘们е°ҶеҺҹе§Ӣзҡ„й•ҝи§Ҷйў‘иҪ¬жҚўдёәеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“пјҢ
е°Ҫз®ЎеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMsпјүе’ҢеӨ§еһӢи§Ҷи§ү - иҜӯиЁҖжЁЎеһӢпјҲVLMsпјүеңЁи§Ҷйў‘еҲҶжһҗе’Ңй•ҝиҜӯеўғеӨ„зҗҶж–№йқўеҸ–еҫ—дәҶжҳҫи‘—иҝӣеұ•пјҢеҮҶзЎ®зҺҮиҝӣдёҖжӯҘжҸҗй«ҳеҲ° 76.0%гҖӮ
дёҚеҗҢдәҺд№ӢеүҚзҡ„и§Ҷйў‘жҷәиғҪдҪ“жЎҶжһ¶дҫқиө–дәҺжүӢеҠЁи®ҫи®Ўзҡ„еӣәе®ҡе·ҘдҪңжөҒзЁӢпјҢDVD ејәи°ғе…¶дҪңдёәжҷәиғҪдҪ“зҡ„иҮӘдё»жҖ§пјҢеҚійҖҡиҝҮиҮӘ主规еҲ’пјҢ并жҸҗдҫӣдәҶдёҖеҘ—д»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·дҪҝеҫ—жҷәиғҪдҪ“еңЁдёҚеҗҢйҳ¶ж®өжҗңйӣҶдёҚеҗҢзІ’еәҰзҡ„дҝЎжҒҜгҖӮеҖҫеҗ‘дәҺиҝҮж—©з»“жқҹжҺЁзҗҶгҖӮд»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·йӣҶд»ҘеҸҠдҪңдёәжҷәиғҪдҪ“еҚҸи°ғеҷЁзҡ„ LLMгҖӮйҖҡиҝҮз»ҹдёҖе°Ҷи§Ҷйў‘еҲҶеүІжҲҗзҹӯзүҮж®өпјҲдҫӢеҰӮ 5 з§’пјүпјҢ
(3) её§жЈҖжҹҘпјҲFrame InspectпјүпјҢеҸіпјҡLVBench дёҠзҡ„жҖ§иғҪжҜ”иҫғгҖӮд»ҺиҖҢиөӢдәҲжҷәиғҪдҪ“иҮӘдё»гҖҒеҶізӯ–е’ҢиЎҢеҠЁжқҘи§ЈеҶій—®йўҳгҖӮжңүж•Ҳең°е°ҶеҺҹе§ӢжҹҘиҜўеҲҶи§ЈдёәйҖҗжӯҘз»ҶеҢ–зҡ„еӯҗжҹҘиҜўжқҘи§Јзӯ”й—®йўҳгҖӮйҖүжӢ©е…·жңүйҖӮеҪ“еҸӮж•°зҡ„е·Ҙе…·жқҘд»ҺзҺҜеўғдёӯйҖҗжӯҘиҺ·еҸ–дҝЎжҒҜпјҢDVD д№ҹжҢҒз»ӯи¶…и¶ҠдәҶе…ҲеүҚзҡ„жңҖе…ҲиҝӣжҖ§иғҪгҖӮ

еӣҫ 3пјҡдёҚеҗҢеҹәзЎҖжЁЎеһӢеңЁжҷәиғҪдҪ“дёӯзҡ„иЎҢдёәеҲҶжһҗгҖӮ" cms-width="677" cms-height="547.859" id="5"/>иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮзүҮж®өе’Ңеё§зә§еҲ«зҡ„еӨҡзІ’еәҰдҝЎжҒҜпјҢ并ејәи°ғдәҶжҺЁзҗҶжЁЎеһӢеңЁж•ҙдёӘжҷәиғҪдҪ“зі»з»ҹдёӯзҡ„е…ій”®дҪңз”ЁпјҡжӣҙжҚўжҺЁзҗҶжЁЎеһӢпјҲеҰӮдҪҝз”Ё OpenAI o4-mini жҲ– GPT-4oпјүдјҡеҜјиҮҙжҖ§иғҪдёӢйҷҚпјҢ

и®әж–Үж ҮйўҳпјҡDeep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/2505.18079
жң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қж–°йў–зҡ„жҷәиғҪдҪ“ Deep Video Discovery (DVD)пјҢ DVDВ д»ҘиҝҷдёҖз®ҖжҙҒжңүж•Ҳзҡ„ agentic жЎҶжһ¶еңЁйқһеёёе…·жңүжҢ‘жҲҳжҖ§зҡ„ LVBench дёҠд»ҘВ 74.2%В зҡ„еҮҶзЎ®зҺҮеӨ§е№…и¶…и¶ҠдәҶд№ӢеүҚзҡ„е·ҘдҪңгҖӮ